How does it Work?¶
Classification vs Regression-based¶
There are two main ways of going about object detection:
Classification based algorithms: There are mainly two stages in classification based algorithms.
In the first stage, it will select a bunch of Region of Interest (ROI) in the image where the chances of objects are high.
In the second stage, it will apply a Convolution Neural Network to these regions to detect the presence of an object.
One of the problems with this method is, we have to execute the detector in each of the ROI, and that makes is slow and computationally expensive. One example of this type of algorithm is R-CNN.
Regression-based algorithms: In this algorithm, there is no selection of interesting ROI in the image, instead of that, it will predict the classes and bounding boxes for the entire image at once. This makes detection faster than classification algorithms.
YOLO (“You Only Look Once“) is an example of a regression-based algorithm. The YOLO detector is very fast so it is a great choice for self-driving cars and other applications where real-time object detection is required.
Detecting Objects¶
The YOLO detector predicts the class of an object, its bounding boxes and the probability of the class of object in the bounding box. Each bounding box has the following parameters
The Centre position of the bounding box in the image
The width of the box
The height of the box
The class of object
Each bounding box is associated with a confidence score, it is the probability of a class of object in that bounding box.
The image (or frame of video) is split into a grid of many cells. The cell in which the centre of an object resides, is the cell responsible for detecting that object.
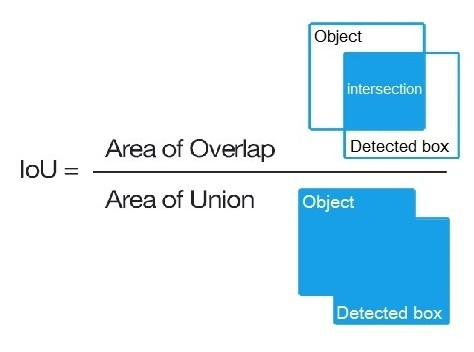
The confidence represents the IOU between the predicted box and the actual box (the ground truth box).
IOU stands for Intersection Over Union and is the area of the intersection of the predicted and ground truth boxes divided by the area of the union of the same predicted and ground truth boxes.
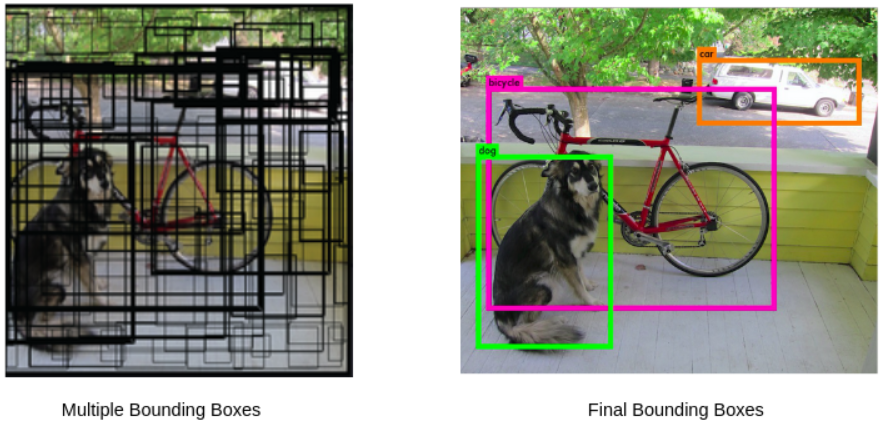
Non-max suppression¶
Each cell can have multiple bounding boxes typically 5. This means for a 19x19 grid there can be a total of 1805 bounding boxes for 1 image.
Most of the bounding boxes in a cell may not have an object. To filter these out the confidence score of the box is used. A non-max suppression process will eliminate the unwanted bounding boxes and only the highest scoring boxes will remain.

Here is some example code of a nms algorithm. Although it can be imported from libraries:
import numpy as np
import cv2
def non_max_suppression(boxes, classes, max_bbox_overlap, scores=None):
"""Suppress overlapping detections.
Original code from [1] has been adapted to include confidence score.
[1] http://www.pyimagesearch.com/2015/02/16/
faster-non-maximum-suppression-python/
Parameters
----------
boxes : ndarray
Array of ROIs (x, y, width, height).
max_bbox_overlap : float
ROIs that overlap more than this values are suppressed.
scores : Optional[array_like]
Detector confidence score.
Returns
-------
List[int]
Returns indices of detections that have survived non-maxima suppression.
"""
if len(boxes) == 0:
return []
boxes = boxes.astype(np.float)
pick = []
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2] + boxes[:, 0]
y2 = boxes[:, 3] + boxes[:, 1]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
if scores is not None:
idxs = np.argsort(scores)
else:
idxs = np.argsort(y2)
while len(idxs) > 0:
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
overlap = (w * h) / area[idxs[:last]]
idxs = np.delete(
idxs, np.concatenate(
([last], np.where(overlap > max_bbox_overlap)[0])))
return pick
Making detections¶
To make detections in the first place there is an entire Convolutional Neural Network behind the scenes with many different types of layers and activation functions. cspdarknet53 has been developed as a backbone for YOLOv4 and this is what is currently used. The code is shown below. I reccomend researching CNNs in more detail and how they are the standard for image recognition:
def cspdarknet53(input_data):
#YOLOV4
input_data = common.convolutional(
input_data, (3, 3, 3, 32), activate_type="mish")
input_data = common.convolutional(
input_data, (3, 3, 32, 64), downsample=True, activate_type="mish")
route = input_data
route = common.convolutional(route, (1, 1, 64, 64), activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 64, 64), activate_type="mish")
for i in range(1):
input_data = common.residual_block(
input_data, 64, 32, 64, activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 64, 64), activate_type="mish")
input_data = tf.concat([input_data, route], axis=-1)
input_data = common.convolutional(
input_data, (1, 1, 128, 64), activate_type="mish")
input_data = common.convolutional(
input_data, (3, 3, 64, 128), downsample=True, activate_type="mish")
route = input_data
route = common.convolutional(route, (1, 1, 128, 64), activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 128, 64), activate_type="mish")
for i in range(2):
input_data = common.residual_block(
input_data, 64, 64, 64, activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 64, 64), activate_type="mish")
input_data = tf.concat([input_data, route], axis=-1)
input_data = common.convolutional(
input_data, (1, 1, 128, 128), activate_type="mish")
input_data = common.convolutional(
input_data, (3, 3, 128, 256), downsample=True, activate_type="mish")
route = input_data
route = common.convolutional(route, (1, 1, 256, 128), activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 256, 128), activate_type="mish")
for i in range(8):
input_data = common.residual_block(
input_data, 128, 128, 128, activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 128, 128), activate_type="mish")
input_data = tf.concat([input_data, route], axis=-1)
input_data = common.convolutional(
input_data, (1, 1, 256, 256), activate_type="mish")
route_1 = input_data
input_data = common.convolutional(
input_data, (3, 3, 256, 512), downsample=True, activate_type="mish")
route = input_data
route = common.convolutional(route, (1, 1, 512, 256), activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 512, 256), activate_type="mish")
for i in range(8):
input_data = common.residual_block(
input_data, 256, 256, 256, activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 256, 256), activate_type="mish")
input_data = tf.concat([input_data, route], axis=-1)
input_data = common.convolutional(
input_data, (1, 1, 512, 512), activate_type="mish")
route_2 = input_data
input_data = common.convolutional(
input_data, (3, 3, 512, 1024), downsample=True, activate_type="mish")
route = input_data
route = common.convolutional(
route, (1, 1, 1024, 512), activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 1024, 512), activate_type="mish")
for i in range(4):
input_data = common.residual_block(
input_data, 512, 512, 512, activate_type="mish")
input_data = common.convolutional(
input_data, (1, 1, 512, 512), activate_type="mish")
input_data = tf.concat([input_data, route], axis=-1)
input_data = common.convolutional(
input_data, (1, 1, 1024, 1024), activate_type="mish")
input_data = common.convolutional(input_data, (1, 1, 1024, 512))
input_data = common.convolutional(input_data, (3, 3, 512, 1024))
input_data = common.convolutional(input_data, (1, 1, 1024, 512))
input_data = tf.concat([tf.nn.max_pool(input_data, ksize=13, padding='SAME', strides=1), tf.nn.max_pool(
input_data, ksize=9, padding='SAME', strides=1), tf.nn.max_pool(input_data, ksize=5, padding='SAME', strides=1), input_data], axis=-1)
input_data = common.convolutional(input_data, (1, 1, 2048, 512))
input_data = common.convolutional(input_data, (3, 3, 512, 1024))
input_data = common.convolutional(input_data, (1, 1, 1024, 512))
return route_1, route_2, input_data